算法简介:空取奇思的手艺
接下来的内容是关于链剖分的,没错,就是链剖分,那个每次去和线段树凑在一起用的算法,其实线段树早就已经讲过很久了,这个链剖分着实讲的有点晚,不过无伤大雅,这次讲清楚便是。
友情链接:
链剖分大概分为三个主流的:
- 树链剖分(也叫重链剖分)
- 实链剖分(就是熟知的恶魔
LCT) - 长链剖分(和重链剖分齐名的一种剖分方式)
这一篇的内容就是关于重链剖分的,后续可能会接着把几个连剖都搞完。
算法演示:巧言贴耳的诱引
算法推导:玄迷灵敏的指法
首先,重链剖分其实是非常形象的。他的名字:重链剖分的重,直接表明了他的主要思路,通过轻重儿子剖分。所谓轻重儿子,我们把一个节点 $u$ 的儿子中,子树(包含那个儿子)的大小中最大的,就是重儿子,记作 son[u] ,S也就是 $u$ 的重儿子。( sz[u] 表示以 $u$ 为根的子树大小)
那么什么叫做以轻重儿子剖分呢?我们在定义下面的内容,父亲连向重儿子的边叫做重边、反之也就是连向轻儿子(不是重儿子的点)的边是轻边。重链就是由重边组成的链,轻链就是轻边组成的链。那么我们可以有下面这张图:
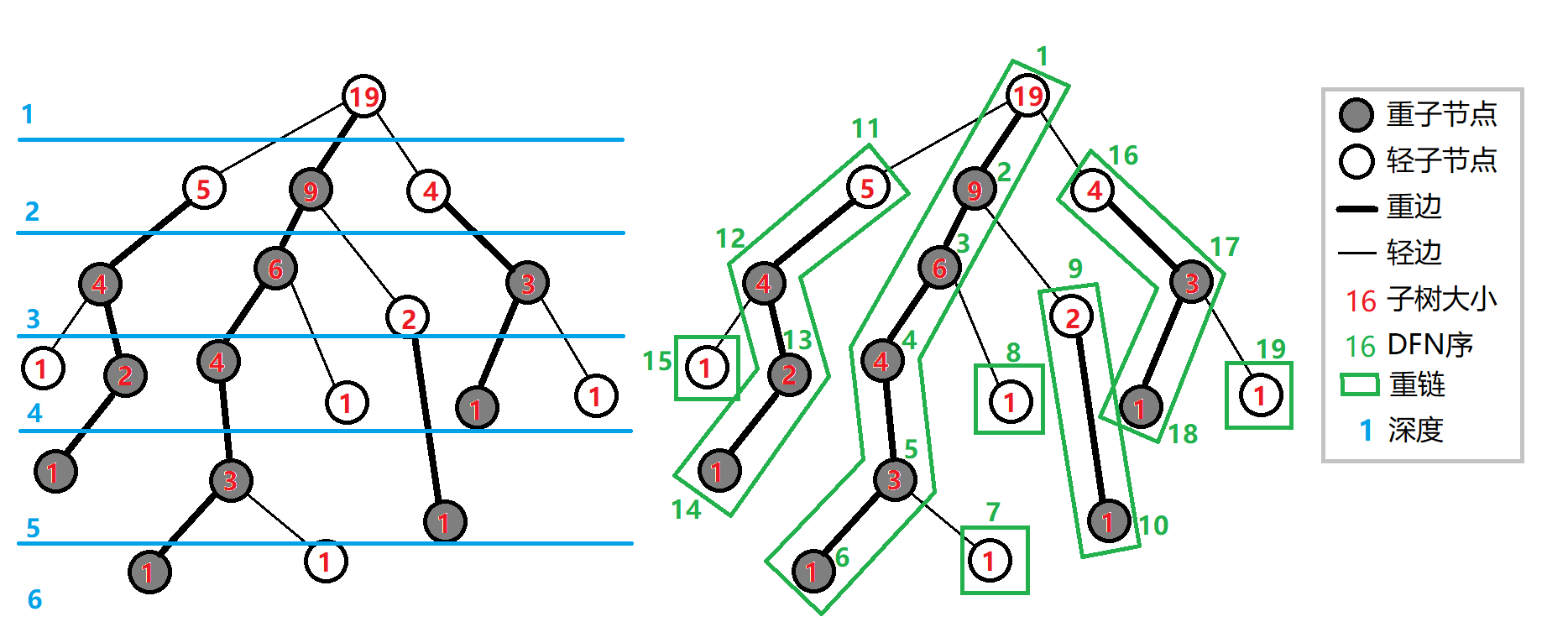
Q:为什么重链里面存在轻儿子?A:显而易见的,所有点都会存在一个重儿子,这也就说明即使是一个点轻儿子也会有自己的重儿子(当然不是叶子)也就是说存在一条重边,那么其实一个轻节点都是作为一个重链的起点存在的。特殊的,对于轻的叶子节点,我们可以认为他是自成一个重链。
OK,那么这里就把重链的基本概念讲完了,但是如果仔细观察一下上面的这张图,会发现它一个与众不同的点:DFS序。正常来讲,一颗树是没有严格意义上一定的 DFS 序的。但是你会发现,他从根节点开始把 DFS 序记为 1,然后他的重儿子的 DFS 序标了 2 然后一路标记下来,发现了什么?优先标记一个点的重儿子,然后剩下的轻儿子没有要求。
这里就说明了一个重要的点,我们在代码实现的时候,DFS 序需要和寻找重儿子等代码分开来写。那么为什么要这样设计呢?我们知道重链剖分的一大作用就是把树按照重链的形式分割开来,这样处理的时候可以整条链整条链的处理,而把一整条重链的 DFS 序标注在一起,这样就可以像处理区间问题的时候一样,搞定问题。
那么接下来还有一个图上没有的信息,就是上面 Q&A 的时候提到的每一条重链的起点。这是为什么需要记录呢?其实也是为了方便处理整条链,我们记录了整条链的起点也就是深度最低的那个结点之后,可以一次性把当前点到这个重链的起点信息直接套用然后掠过那一段路程,这个是树链剖分优化很大的一个地方,后面讲一些应用的时候会用到。
算法模板:熟稔习练的筹谋
其实答题思路,都已经讲过了,这里主要是把上面说过的几个信息的大致名称都说一说。
1 | int fa[MaxV], dep[MaxV]; |
算法应用:穿越隐秘的通术
那么首先,我们说过树链剖分的一大作用就是和线段树一起用,那么其实为什么也说过了,人家专门把 DFS 序变成连号让你以区间的形式处理整条链,很不错。重链剖分要处理的主要是一个经典问题:树上两个点所在路径上的信息,那么这个是什么呢?我们还是拿出刚刚的那张图
比如说我们处理 DFS 序为 14 还有 DFS 序 为 7 的两个点所在的路径。按照直接跳过整个重链的思路,我们就会是这样:
- 首先看,序号 14 的所在重链顶端点 11 深度为 2 ;序号为 7 的所在重链顶端点 7 深度为 6 ;显而易见他们不在同一个重链,判断两个点不在同一个重链的原因是如果两个点在同一个重链,不管跳的是哪一个点,都会跳出两个点所在的路径(当然也有可能是卡在 LCA 的点上),然后呢看那个重链的顶端深度深,这也是显然的,如果跳了深度浅的那一个点,也是有风险跳出他们路径的。
- 那么我们就记录下重链顶端节点 7 到当前节点 7 这一段的信息。然后从序号 7 跳到它所在重链顶端点的父亲 ,也就是序号 5 。这一步为什么要跳到顶端的父亲而不是顶端,是应为显然的顶端的顶端还是顶端,这显然死循环,一个简单的推理。
- 那么反复操作,这次五号点的顶端点 1 深度为 1;然后刚刚的 14 号点的顶端点 11 深度为 2 ;于是把 14 号点到它的顶端点信息记录,然后跳到他的顶端点的父亲也就是 1 。
- 最后发现他们都已经在同一条重链上了,所以直接记录点 1 到点 5 的信息即可。
我们可以有这样的实例代码:
1 | inline Calc(int u, int v) { |
不难发现,树链剖分不断跳跃的过程其实也是寻找 LCA 的过程。那么他的复杂度如何呢?其实就是前段时间发的一个文章的思路了
友情链接:
那么这个思维体现在树剖上,又是什么呢?我们注意到重儿子的一大特点,所在子树的大小最大,如果我们走到了一个轻儿子,那么大小一定至少会减少一半(经典性质,不知道的想想为什么)那么一直分下去,复杂度即为 $O(\log n)$ 但是说他的常数据说是小于倍增求 LCA 的,这个我不会证明(其实不好评价,应该是看建出来的树的)
那么还有一个忘记讲的性质:树剖标记的整个子树的 DFS 序也是连在一起的,这个显然,也就是说子树信息也是可以直接用线段树等数据结构维护的。
算法实战:违背心绪的微笑
查看相关算法标签喵!