文章总览:群星岸落之夜
如你所见,这篇文章的主题是概率与期望。众所周知,概率与期望早就占领了各大领域,比如说投篮的命中率可以表达一个选手的投篮水准,竞赛题目设置很多测试点来测试代码本质是一种抽样调查,等等等等。但是说概率与期望,在初中或者高中课本中都是占比非常大的部分(刚刚好我也打算顺手学了),所以这篇文章的前半部分注重于一些课本上的基础知识介绍与讲解,后面会浅浅的说一些信竞方面的概率期望。
下为本文大纲:
概念基础:穿过锁孔之风
概率定义:这是魔法哟
关于概率的定义,你可能会说:“这玩意不是烂大街了嘛吗?还有人不会的?”正确的,概率的定义其实大家都知道是那个意思,可是实际上从稍微严谨的角度出发的概念以及一些性质可能并不广为人知,我们要学概率,就要从最基础概念开始:概率的基础——事件。
对于一个事件,可以是世间万物,比如说下面几个都可以是事件:
- 在一个既有青蛙又有兔子的娃娃机抓娃娃,抓出了一只青蛙(概率事件)
- 太阳从西边升起(不可能事件)
- 在一个既有青蛙又有兔子的娃娃机抓娃娃,抓出了一只兔子(概率事件)
- 从高楼跳下会摔亖(必然事件)
我们可以探讨一下事件之间的关系:
在上面所说的抓娃娃事件中,我们知道了娃娃机里既有青蛙又有兔子,那么抓出一只青蛙是有可能的,抓出一只兔子也是有可能的,问题并没有说明有没有除了青蛙与兔子以外的动物,如果有的话,那么这两个事件就是互斥的事件,即为“不可能同时发生”。
但是说,如果这个娃娃机是只有青蛙和兔子的,那么这时候我们抓出来的娃娃一定不是青蛙就是兔子,显然的这两个事件也是不可能同时发生,但是除了这两种事件不会有别的了,这时候它就是一个特殊的互斥关系,被称为对立。
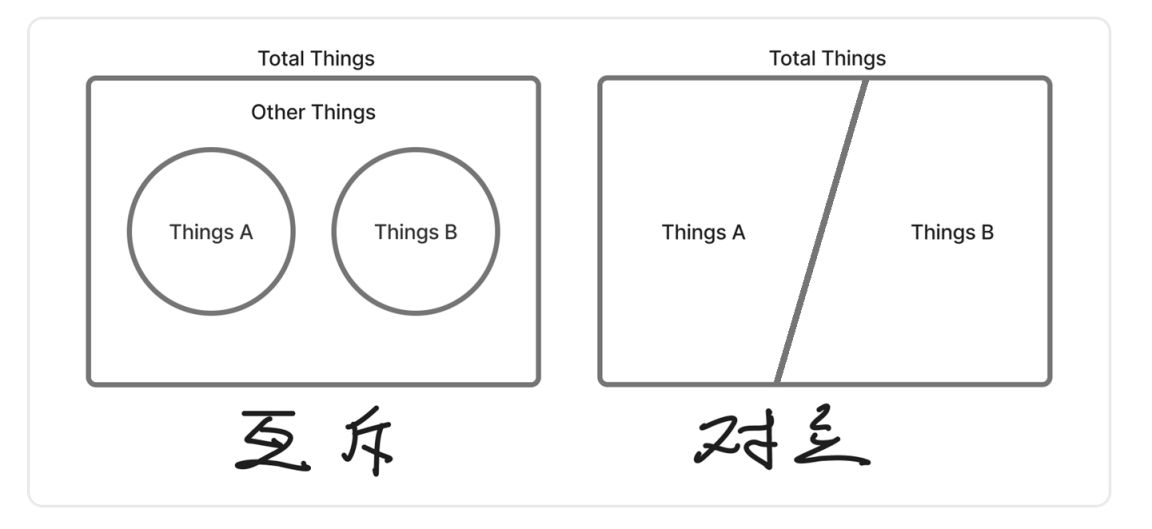
那么除了这两种事件关系,实际上还有一个,那就是独立。与上面两个关系不同,这两个关系都是不可以同时发生的,那么相对的,可以同时发生的事件关系,就是独立事件。比如说下面两个事件:
- 投骰子,投出六
- 陨石撞地球
这两个事件显然是可以同时发生的,这就是一组独立事件,文氏图应该就不用我画了罢(doge
那么上面介绍了事件的定义和它们之间的简单关系,那么概率是什么呢?关于概率我们需要先教科书式的介绍一下下面这些概念:
- 样本点:一种结果,我们抽出样本中的一个,代表整体可能性的一种结果,记作 $\omega$ 。
- 样本空间:所有样本点的集合,记作 $\Omega$ 。
- 事件:样本空间的子集,若干结果的集合,用表示集合的方式来表示即可。
我们举一个简单的例子,对于一次全班的考试中,要考虑考试的结果,对于 $x\in[0,100]\cap\mathbb Z$,“考试得了 $x$ 分”就是一个样本点,记作 $\omega_x$。那么所有 $\omega_x$ 的集合就是样本空间,显然的一共有 $101$ 个样本在里面。对于事件“考试及格”所对应的集合就应该是 $A=\{\omega_x\mid 60\le x\le 100\}$。
那么说完了这些,概率到底是什么呢?
本质上来讲,概率是一个从事件对应到一个实数的函数 $P$。在有限样本空间中,每一个样本点被赋予了一个概率 $P(\omega)$,而构成事件 $E$ 的所有 $P(\omega)$ 之和即为这个事件的发生概率,通常来讲,概率有如下性质:
- 非负性:对于任意事件 $A$ 都有 $P(A)\ge0$;
- 正规性:$P(\Omega)=1$
- 可加性:如果事件 $A_1,A_2,\dots,A_k$ 两两互斥,那么 $P(\cup A_i)=\sum P(A_i)$,其实刚刚说的构成事件 $E$ 的 $P(\omega)$ 之和就是这个性质的一个表现。
那么这是概率的一些性质,概率的实际意义是什么呢?这是一个至今具有争议的问题,主要有两个主流的关于概率实际意义的观点:
- 频率学派:认为概率是相对频数的极限,是一种客观属性。这其实是大多数人一开始接触概率时的看法。这一说法适用于可以反复观测的事件,随着观测次数趋于无穷,事件发生的相对频数会越来越趋近于真正的概率。
- 贝叶斯学派:认为概率描述的是信心的程度,带有一些主观的成分。比如,可以说“明天下雨的概率是 $90\%$”,但显然我们无法多次观测这一事件。这里的 $90\%$ 代表我们对于“明天下雨”这一事件的信心,将来如果我们得到的新的数据(比如云层的变化),我们可能会对这一信心进行修正。
这两个东西了解即可,没啥太大用处,接下来看如何计算简单的概率。
简单计算:你开窍了吗
在最最开始学习概率的时候,我们可以举一个例子:投骰子投出偶数的概率是多少?显然的,在一个骰子上,偶数有 $2,4,6$ 三种,一共有六面,概率就是 $3/6$ 即 $1/2$。
这种目标情况数量和总情况数量的比值,就是概率最基本的计算公式,被称为古典概型。
那么不难看出,古典概型的本质其实就是计数问题,而我们学过的最最基本的计算方案数量的方式,无非就是暴力枚举和排列组合,接下来看两个例题:
友情链接:
例题一:在写有 $1\sim 6$ 的卡牌中不放回卡牌地连抽两张卡片,抽到两张卡牌的和是 $4$ 的倍数的的概率是多少呢?
这道题就是一个经典的暴力枚举+排列组合的题目,首先总方案数很显然是 $C_6^2$,然后来看有多少种可能抽出的两张卡牌之和是四的倍数的,由于不分先后顺序,可以列出下表:
| + | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 2 | 3 | 4 | ||||
| 3 | 4 | 5 | 6 | |||
| 4 | 5 | 6 | 7 | 8 | ||
| 5 | 6 | 7 | 8 | 9 | 10 | |
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
加粗的数即为四的倍数的方案,数一数,一共有六种。由刚刚的古典概型公式可以得到答案:
很简单,好的看下一题:
例题二:花博会有 $A,B,C,D$ 四个展馆,甲乙两人每人选择 $2$ 个参观,在他们选择的展馆恰好有一个相同的概率是多少呢?
那么这道题应该有一个大的考虑方向,总情况数是显然的,$(C_4^2)^2$ 意为两个人各选两个,而且最终顺序显然是不用被考虑的。目标情况数的话我们由于恰好有一个相同,所以说我们可以优先选出这个相同的,剩下两个不能相同,对应的表示方法就应该是 $C_4^1\times C_3^1\times C_2^1$,搞定。
不过另外的,由于选出来了一个目标以后,两人只能在剩下的三个选出不同的,并且由于两个人是有差异的,所以是要考虑顺序的。综合来讲,方案数也可以是 $C_4^1\times A_3^2$ 。
但是不管怎么说,最终的答案一定是固定的:
这就是古典概型,简单事件的概率计算,但是通常来讲题目里不止是简单事件,更多的是复杂事件,我们来看看接下来如何计算复杂事件的概率——加法与乘法原理。
加法与乘法原理其实是排列组合里面的一种概念,大致含义就是分类用加法、分步用乘法。那么在概率中,这个规律也还是适用的,我们可以简单的看一道例题来理解一下。
例题三:发电报,发送 $0$ 时有 $\alpha$ 的概率收到 $1$,$(1-\alpha)$ 的概率收到 $0$;在发送 $1$ 时有 $\beta$ 的概率收到 $0$,$(1-\beta)$ 的概率收到 $1$ 。发送信息的时候要把某一个信息连发三遍,每一次发送信息都是独立的,收到的信息中出现次数多的就是译码,现在问发送 $1$ 时,有多少概率接受到的也是 $1$ ?(其中 $0\lt\alpha,\beta\lt1$ 即概率合法且均为概率事件)
我们可以轻松的写出下面这样的分类讨论:
- 发送三个一,接收三个一:显然的,由于每次发送信息独立,概率为 $(1-\beta)^3$。
- 发送三个一,接受两个一:接收两个一的概率是 $(1-\beta)^2$,接收一个零的概率是 $\beta$,一共有三种排列方式,全部乘起来就是答案,$3(1-\beta)^2\beta$ 就是这个情况的概率。
- 显然剩下的没有可能了。
那么这两个情况都是符合条件的,概率相加即可,最终答案应该是:
这里就体现了分类相加分步相乘的思想,分类讨论出来的每个结果相加,分讨内部的各种情况都是乘起来算,这就是所谓的加法与乘法原理。
但是说这里我们不得不提出一个问题:对于任意事件 $A,B$,始终满足 $P(AB)=P(A)P(B)$ 吗?也就是:对于任意两个事件同时发生的概率始终等于两个事件单独发生的概率的乘积吗?(这里 $P(AB)$ 是 $P(A\cap B)$ 的简写)
事实上并不是。这个命题满足的前提条件是事件 $A,B$ 互斥,这也不难理解。如果两个事件存在交集的话,这就意味着这个事件在触发的同时也有可能会触发另一个事件,这显然概率就被我们重复算了。
那么这时候,我们又该如何计算这类的概率呢?欢迎来到下一幕——条件概率。
条件概率:打开的格局
为了解决一个事件不互斥时候的概率计算,我们不得不引入条件概率。关于条件概率的定义,大概是我们用符号 $P(B\mid A)$ 表示:在 $A$ 发生的前提下,$B$ 有多少可能发生,计算方法也简单易懂,看看下面的图就知道了:
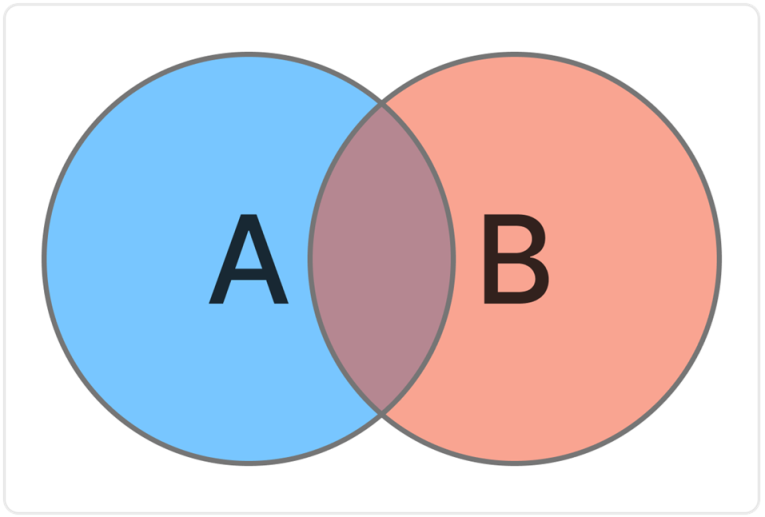
因为前提条件是 $A$ 发生,所以说我们只需要在事件 $A$ 的这个蓝色圆内考虑问题,而在蓝色圆圈内 $B$ 发生的概率是显然的,即:
所以说依照定义,上面那一个命题的正确形式应该是 $P(AB)=P(A)P(B\mid A)$,这是条件概率的基本定义,接下来可以简单的看一些题目感受一下。
例题四:一共有 $52$ 张扑克牌,没有大小王,无放回地连抽两次,两次都抽到 $A$ 的概率有多少?如果第一次抽到 $A$ 的前提下,第二次抽到 $A$ 的概率是多少?
显然的这道题可以不用条件概率,不过配合一下,现在正在讲条件概率如何解题。首先来看第一个问题,两次抽到 $A$ 的概率有多少?这个问题直接上古典概型,不难得到答案应该是:
第二小问明显是一个条件概率,如果我们设事件 $A$ 是第一次抽出 $A$,事件 $B$ 是第二次抽出 $A$,那么显然在条件概率中的分母就是 $P(A\cap B)$ 也就是两次都抽出 $A$ 的概率,这个已经在第一问求出来了,剩下的第一次抽出 $A$ 的概率是非常好求的,所以最终答案应该是:
感觉很简单,再来一个
例题五:某班同学有 $60\%$ 的同学玩原神,$50\%$ 的同学玩崩铁,$70\%$ 的同学玩原神或崩铁,那么在这个班级里玩崩铁的同学里随机抽一个,则这个同学也玩原神的概率是多少?
这个题目有点文字把戏,这里“玩原神或崩铁”的意思应该是“玩原神和玩崩铁”的人之和,那么动用小学数学知识我们就能画出下面这样的韦恩图:
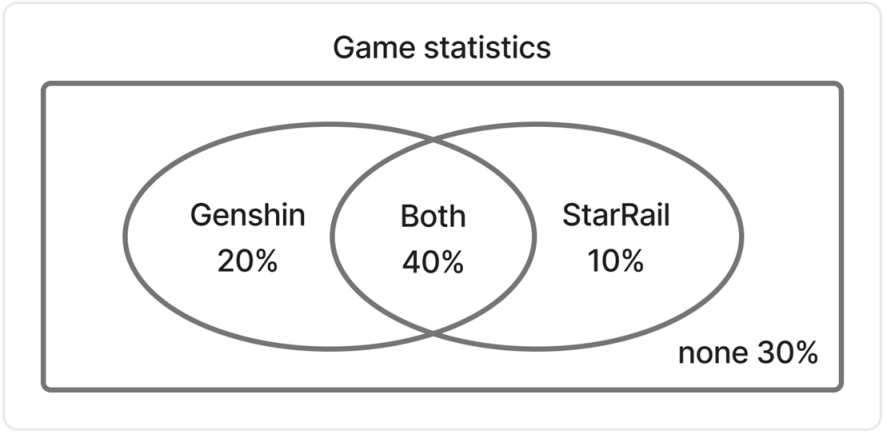
这个甚至一眼丁真就可以做:
这样就可以算是解锁了概率的基础计算方法了,接下来我们来看进阶的两个公式。
特殊公式:看看好看的
首先第一个公式,全概率公式。这个公式的思想就是分类+分步,把一个难以计算的事件分为几个小事件,逐个击破,最终得到答案,所以说它表现出来应该是:
直接干巴巴的看可能看不出什么,我们来见几个直观的例子。
例题六:某同学在一次考试中,$8$ 道单选题中有 $6$ 道有思路,$2$ 道没思路,有思路的有 $90\%$ 的可能性能做对,没思路的有 $25\%$ 的可能性做对,则他在 $8$ 道题中随意选择一道题,做对的概率是多少呢?
很容易注意到的就是每一道题分成了有思路和没思路两部分,这样就导致整个事件的概率变得难以计算。这时候就只需要拿出我们最最最最最原始的方法,树形图。由于属性图的优秀性质,我们做概率题的时候特别喜欢用它来表示事件与事件之间的关系。
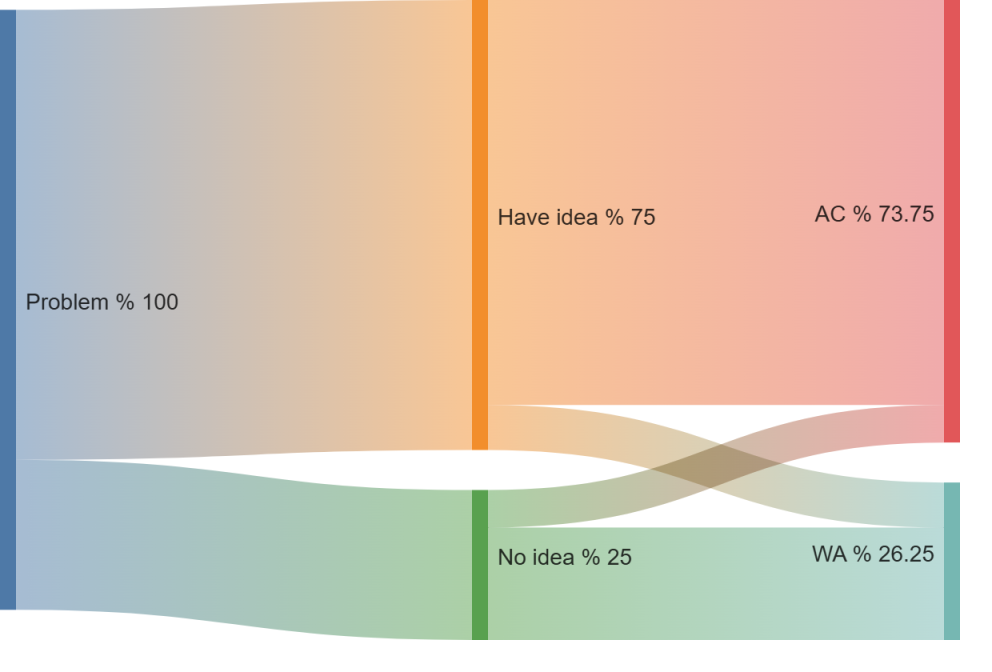
在所有问题中,显然的随机抽一道抽出有思路的问题和没思路的问题分别是 $75\%$ 和 $25\%$,在有思路的情况下,做对这道题目的概率是 $90\%$,根据上面的分步相乘思想,这一分支做对的概率是 $75\%\times90\%$。对应的,在没有思路的情况下,作对题目的概率只有 $25\%$,整个分支的概率应该是 $25\%\times25\%$。最有依据分类相加的思想,总共作对的概率就是 $73.75\%$ 即 $59/80$。
这就是全概率公式思想的一个体现,把问题拆分后,分步相乘分类相加。
第二个概率公式是贝叶斯公式,贝叶斯公式主要是针对条件概率的,并且其计算过程也天生包含全概率公式,还是老规矩,先放公式:
乍一看比刚刚更加玄学了,不过仔细观察一下,分子是我们之前说过的条件概率计算两个事件同时发生的概率,而分母是刚刚学过的全概率公式,这个方法在题目中的具体表现,可以简单的看一看:
例题七:旅行者打算凹两层深渊,第一层旅行者满星的概率为 $0.6$,但由于旅行者好胜心过强,第二层的满星概率会受第一层表现的影响,若其第一层满星,则第二层满星的概率依然为 $0.6$,但旅行者一旦被击败,其下一层的满星概率迅速降为 $0.1$。 小美第二层深渊获得满星的概率是多少?已知小美第二层满星,则其第一层未满星的概率是多少?
第一问很简单,直接上全概率公式可以得到答案是 $0.6\times0.6+0.4\times0.1=0.4$。
第二问就要用到贝叶斯公式了,分母已经得到,分子我们就要明确一点,事件 $A$ 和 $B$ 到底都是谁。显然的根据题目我们知道 $A$ 应该是第一层未满星的概率,$B$ 是第二层满星的概率,当他们俩同时发生的时候,显然的就对应了概率 $0.4\times0.1=0.04$,那么最终的答案就很显然了:
这就是贝叶斯公式和全概率公式的解释,事实上这两个计算公式的思想都是类似的,主要靠大家理解概率问题的本质。
概念进阶:进入盛夏之门
Warning:以下部分除了期望概念其他的都针对于高中数学☠️
期望概念:冷漠的诚实
关于期望的概念,我们首先要了解的是分布列的概念。首先分布列就是一个随机变量所对应的概率,所谓随机变量,可以认为是一个样本空间所包含的样本点,每一个样本点所出现的不同概率就是它所对的概率。
| X | $x_1$ | $x_2$ | $\cdots$ | $x_i$ | $\cdots$ | $x_n$ |
|---|---|---|---|---|---|---|
| P | $p_1$ | $p_2$ | $\cdots$ | $p_i$ | $\cdots$ | $x_n$ |
而期望就可以理解为这个随机变量在概率意义下的平均值,不过说这个平均值并不是我们所说的那种加起来还要除以个数的平均值,由于我们要算在概率意义下的平均值,对于整个样本空间来说,概率总和应该是只有 $1$ 的,所以最后我们要除以的量应该是 $1$。
这就是期望的计算公式,一般来讲常规的编程题目考的都是期望。
我们也可以举一个简单的例子来看一下期望的计算:
例题八:抽卡,出金有 $1.6\%$ 的概率,会带来 $8$ 的高兴值;出紫有 $13\%$ 的概率,会带来 $4$ 的高兴值;剩下的保底出蓝,会带来 $1$ 的高兴值。问一次单抽期望给我们带来多少高兴值?
明显的期望题,答案是:
太简单了
方差概念:饥饿的地景
方差的话就是更加少见的东西,一般来讲只会在数学大题里面出现,竞赛不会说,不过我也浅浅的介绍一下。方差也是一个基于分布列的概念,大概来讲的话,是数值偏离平方期望值。这里涉及到三个重点:偏离、平方、期望,这与方差的计算公式有莫大的联系,我们首先来看方差的计算公式:
这个公式非常好的体现了刚刚的点,偏离对应的就是被平方的数,这是方差的本质。平方顾名思义就是这个公式中的平方运算,这个运算的性质可以给我们的优点有很多:
- 正确性:显然的,如果存在了负数的偏离量,这时候求和就会导致抵消了其他人的偏移量,与正经的期望值就没什么区别了。
- 可辨性:相对于绝对值运算,平方运算能更加放大偏移量,让我们直观的注意到高偏移度所对应。
第三点期望,这个很直观,每一个偏移平方的期望值,我们把偏移平方看作一个整体的话,确实就和期望的计算公式体现出了极高的相似性,也能很好的平均便宜平方,这就是方差。
虽然但是,房产查的计算公式非常繁杂,但是我们还有另外一个公式,显得会比较好记:
也没什么好说的,这玩意是真正的没有考频,一点没有,记住几个公式即可。
线性相关:视界外来信
接下来的概念是线性相关,线性相关也可以算作一个分布列上的概念,或者说更广泛的,线性相关可以适用于一些数列的函数关系。不过说这个函数关系是平均的,或者说是拟合的,即这个函数并不是数据严格以这个拟合的直线分布,而是会存在分布在这个直线周围的情况。
对此为了判定数据线性相关性的强弱,我们要引入线性相关系数的概念,首先是计算公式:
对于这个系数的取值范围,其实是在 $[-1,1]$ 的区间内的。其中 $|r|\rightarrow 0$,就表示这组数据的线性相关性极弱;相对的如果 $|r|\rightarrow 1$,就说明这组数据的线性相关性强,其中, $1$ 表示正相关性,$-1$ 表示负相关性。一般来说,线性相关系数的绝对值在 $0.75$ 及以上的,我们都可以说是线性相关性强的数据。
我们来解析一下这个式子的组成部分:
分子的组成部分是所有 $x$ 和平均 $x$ 值的差乘以所有 $y$ 和平均 $y$ 值之差的乘积,我们可以对于一些线性型函数做一个小对比。众所周知线性函数也就是一次函数(当然常数函数也是,不过常数函数是一个常数比较特殊,这里不对它进行分类考虑)
- 正相关性:即 $x$ 增加时 $y$ 也增加。可以看一下,如果 $x<\bar x$ 且 $y<\bar y\ $那么最终的两个差都应该是负的,最后乘起来就是正的。相反如果都大于平均值,显然乘积也都是正的。
- 负相关性:这是与刚刚正相关性相反的,推理过程没有差异,自行理解一下。
最后求和就表示了相关性的整体综合,理论上如果线性相关性非常强的话,比如说是严格正相关性,那么每一项的乘积都应该是正的,最终的家和就是一个累积了所有正数的一个极限值。相反的如果中间有一个数违背了这个相关性,可能就会导致造成的贡献比期望值小,或者直接变成负的,这样就会导致相关系数的绝对值变小。
但是我们还有一个疑问,在一个一次函数上真的能取到 $\pm 1$ 的极限值吗?我们简单证明一下:
设一次函数 $y=kx+b$ 中且 $k\neq 0$,我们在公式中代入一次函数的解析式。
分母也可以算:
然后把这些式子全都代入到公式里:
所以说再一次函数中显然的 $r$ 可以取到 $\pm 1$ 的极值,这也是为什么 $k$ 不能等于 $0$ 的原因。
但是注意到关于线性相关系数我还给出了另外一个公式,那么如何理解这个公式呢?
关于这个公式,我们可以先从刚刚的出发,看看能不能推出这个式子。这个式子在考题中的主要运用大概就是:考试的时候给了你一堆数据,然后给了你第一个式子,但是计算繁杂。然后给出的数据里面,有第二个式子的组成部分,你可以直接代入那些数据从而快速求解。所以说可以认为这个式子与第一个式子等价,我们要具备的是在考场上推出这个式子的能力。
首先来看分子:
我觉得这个推导过程中除了要反复用到总和等于总量乘以平均值这一点以外,就是主意好每一个求和符号的范围就可以,其他的没有什么容易混淆的,接下来推分母:
同理,$y$ 的那一项也是一样可以这样推出来的,也就是说我们可以轻松从原始公式中推导出这一个公式,完美!另外关于线性相关系数还有一个辨析点:若线性相关系数 $r=0$,则 $x,y$ 没有相关关系。这显然是错的,线性相关系数等于 $0$ 只能说明 $x,y$ 没有线性相关关系,不能说没有其他相关关系的。
接下来是关于线性拟合的事情,我们知道了线性相关性肯定还不够,肯定会让你判断最终拟合出来的直线是什么。而拟合肯定是一个基于平均值的计算,所以我们想都不用想,拟合出来的直线一定经过点 $(\bar x,\bar y)$。接下来简单介绍一下如何计算拟合后直线的解析式。
我们设拟合后的直线的解析式是 $\hat y=\hat kx+\hat b\ $,关于斜率 $\hat k$,我们有如下的计算公式:
这个公式的含义可以大致理解为,分子是自变量 $x$ 和因变量 $y$ 的变动,分母是单纯的自变量的变动,这个比率其实就是忽略掉截距以后斜率自己的定义。应该是说因为数据减去了平均值,那么对应被抹除的数据也有截距,所以说这个比率应该是等于最终拟合后直线的斜率的。(以上是我纯纯乱编)
那么已经知道了一次函数经过点和斜率,自然可以轻松的算出截距 $\hat b=\bar y-\hat k\bar x$,还有另外一个公式还是和上面一样的推导过程就可以得到的,这里不再赘述。
这是拟合后的直线,那么我们肯定还要关心拟合的好不好,关于拟合后的直线好不好,我们当然也有自己的衡量数据和计算公式,主要呢是残差和决定系数。
残差的这个概念比较好理解,对于单个点来讲,我们一定可以根据拟合出来的直线的公式算出它在直线上的点,而这个真实值和期望值之差,就是残差,写成式子大概就是:$y_i-\hat y_i$。
但是说残差的缺点是很明显的,残差每个点都会有一个,不好汇总计算,而在之前的几个平均意义下的计算公式观察一下也能发现,大家很常规的一个操作是平方、求和、平均,把这几个思想集一身,就可以得到关于决定系数的计算公式:
为什么这里是 $R^2$ 呢?不知道,我感觉理论上来讲 $R^2$ 是不会是负值的,可能这样写单纯为了好看。决定系数是随拟合程度越好而增加的,因为显然如果拟合的好,残差平方和显然是会小于平均值差平方和的,这样就会导致减去的那个分数小,分数小了,整体就会变大,所以说这个决定系数越大,拟合效果越好。
这样就差不多是拟合的全部内容了,接下来要带来的是一些常见的特殊分布,也是常用的三大分布:二项分布,超几何分布还有正态分布。
分布其一:伯努利实验
首先是最最简单最最经典的分布:二项分布。二项分布的精髓在于 $n$ 次独立重复实验即伯努利试验。我们可以从一个例题出发感受一下所谓伯努利试验。
例题九:九条裟罗射中目标的概率是 $0.9$,现在要连续射击 $8$ 次,每一次射击是相互独立的。现在问九条裟罗恰好击中目标三次的概率是多少?至少击中目标一次的概率是多少?最后一次射击才击中目标三次的概率是多少?
首先来看第一问,其实这一个类似的问题已经在前面的例题出现过,就是相互独立这个关键字已经在前文提到过了,就是例题三。由于每一次行动是独立的,所以要单独计算概率,把它当成“分步相乘”计算即可。我们首先不考虑顺序,只需要射中三次,那么概率就是 $(0.9)^3(0.1)^5$,但显然这个问题是考虑顺序的,乘上不同顺序的数量后,就是最终的答案:$C_8^3(0.9)^3(0.1)^5$。
第二问,至少几种目标一次,很显然的是我们如果要分别计算射中一次射中两次等等等等枚举过来计算的话,非常的困难,但是由于最终概率的总量是 $1$,我们只要减去不满足的即可,而显然不满足的是一次都没有射中,这种答案可以非常简单的被表示为 $1-(0.1)^8$。
第三问,可以看为前 $7$ 次射击只射中 $2$ 次,最后一次射中的概率。答案是 $C_7^2(0.9)^3(0.1)^5$。
我们可以从上面的这道例题了解出一个公式,在二项分布中,事件 $A$ 发生的概率为 $p$ 时,那么该事件在 $n$ 次中发生了 $k$ 次的概率就是 $C_n^kp^k(1-p)^{n-k}$,这是毋庸置疑的。
那么在二项分布中,期望和方差会如何变化呢?这个应该是很好计算的,因为每一次事件相互独立,也就是说期望值就应该是试验次数和事件发生概率的乘积,即 $E(X)=nP(X)$;而关于方差呢我们也是一样的,可以先计算单次试验的方差,然后在计算总共的。单次方差其实就是套公式 $E(X^2)-E(X)^2=(1^2p+0^2p)-p^2=p(1-p)$。而还是因为每次试验重复且独立,所以在二项分布中方差可以表示为 $D(X)=np(1-p)$。
现在都知道了每一个问题怎么算了以后,再来做几道简单题来见见世面:
例题十:岩王帝君在铸造摩拉的时候,由于劳累过度,掺进去了几个黄金,已知岩王帝君喜欢把摩拉一百枚一箱,每一箱都有一个黄金。现在他想要把这几个黄金找出来,但又不想吧刚刚铸好的摩拉全融了,于是他想出了两个办法。方法一:在 $10$ 箱中各抽取一枚;方法二:在 $5$ 箱中各抽取两枚。问这两种方法至少发现一枚黄金的概率分别是多少?
我们来从方法一开始算。首先每一箱摩拉都应该是独立的,所以说这道题可以认为就是一个二项分布的问题。我们在上一题中学到了一个技巧,至少发现一枚黄金其实就是总量减去不发现黄金,所以可以算出来答案是 $1-(\frac{99}{100})^{10}$。
关于第二问来说,和第一问应该是差不多的,我们只需要算出每一项抽不出黄金的概率即可。这显然是一个古典概型的问题,抽两枚的方法总共有 $C_{100}^2$ 种,但是能抽不出黄金的有 $C_{99}^2$ 种,然后我们除一下就能发现这里的概率是 $\frac{49}{50}$ ,总的答案就是 $1-(\frac{49}{50})^5$。
然后我们来看一个贝叶斯公式和二项式分布结合的问题。
例题十一:甲乙两人正在举行比赛,采取五局三胜制(当一队赢得三场比赛时,该队获胜,比赛结束)更据以往的数据可以知道,甲获胜的概率是 $\frac{2}{3}$,比赛是不存在平局的,每场比赛都是相互独立的,那么在甲获胜的情况下,比赛一共进行了四轮的概率是多少?
分类讨论。
当比赛进行三场,甲获胜:显然的答案是 $(\frac 2 3)^3=\frac{8}{27}$。
当比赛进行四场,甲获胜:因为甲要获胜,所以最后一场比赛必然是甲赢,前面的三场比赛乙只能赢一场,那么综合一下答案就是 $C_3^1\cdot\frac{1}{3}\cdot(\frac{2}{3})^3=\frac{8}{27}$。
当比赛进行五场,甲获胜:和上面一个思路,$C_4^2\cdot(\frac{1}{3})^2\cdot(\frac{2}{3})^3=\frac{16}{81}$。
然后我们根据贝叶斯公式可以算出答案就是:
那么这基本上就是二项分布的全部内容了,接下来是第二个分布:超几何分布!
分布其二:解读与灵感
同样的,从一道经典题目出发首先来认识一下超几何分布是什么。
例题十二:一个盒子里面有七个白球和三个黑球,现在从里面随机抽出三个,问抽出一个黑球和两个白球的概率是多少?
首先问我们总共从十个球里面摸出三个,有 $C_{10}^3$ 种选法,另外抽出来的三个球中,一个来自于黑球,两个来自于白球的概率是 $C_{3}^1C_7^2$ 种可能,那么总共的来讲,这样的概率就是:
这就是超几何分布的显著特征,物体分类,事实上要总结超几何分布的概率公式特别简单,我们假设一共有 $N$ 个物体,我们从中抽出 $n$ 个,并且其中某一类抽出 $k$ 个,且这一类有 $M$ 个物体,那么计算公式就是:
一样的,我们来了解一下超几何分布下的期望是什么。假设某一类有 $M$ 个物体,并总共有 $N$ 个物体的话,我们可以知道这一类会占总量一定的比率,而且这个比率就是我们第一次抽出它的概率,那么从期望的角度来说,如果我们在这个限定内一直抽,这个比率应该是固定的,这个就是我们学前班就听说过的大数定理,所以可以松动得到在超几何分布的意义下,期望可以表示为 $E(X)=\frac{M}{N}\times N$。
可以看到超几何分布其实并没有什么难点,所以说如果考的话计算量和计算难度就会特别大。
例题十三:在一个盒子中有 $4$ 个红球,$m$ 个黄球,$n$ 个绿球。从中任意的抽取 $2$ 个球,抽出两个红球的概率是 $\frac{1}{6}$,抽出一个红球一个黄球的概率是 $\frac{1}{3}$,那么 $m-n$ 的值是多少?若设抽出红球 $\xi$ 个,那么 $E(\xi)$ 的值是多少?
这就是一个属于计算偏难的超几何分布问题,因为我们面对了一个盒子并且里面有不容种类的球,所以第一眼都能看出是一个考超几何分布的问题,首先来看能不能计算出 $m-n$ 的值。
可以注意到的是给出了两个具体的数据,所以我们的第一反应都应该是能不能列出关于那两个数据的方程:
要解出这个方程很简单,会注意到分母是一样的,所以让一式除以二式,这样把分母消掉以后就可以计算出 $m$ 的值,然后把 $m$ 的值代回任意一个方程里面,就可以解出 $n$ 的值,方程组的答案应该是 $m=3,n=2$。那么最终的答案即为 $m-n=1$。
然后呢就是算出 $E(\xi)$,这个可以直接套用上面讲的公式,算出来答案 $\frac{8}{9}$。
这道题的主要难点就是解出这个方程组(绝对不是因为我算错了才说这道题难)
分布其三:早说是魔法
接下来的内容属于正态分布,正态分布应该是众多分布里面最有名的,我相信你肯定不止一次遇到过这样的图片:
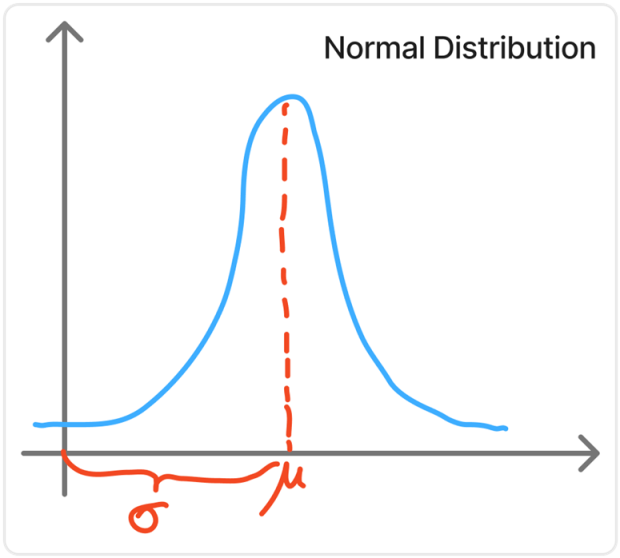
这样就是标准的正态分布了。所谓正态分布,其实就是中间多两头少,这个不难理解,生活中大多数情况都是这样的,比如说一个班里考 $100$ 分的肯定是比较少的,考 $0$ 分的也算比较少的,但大多数人肯定考的分数都是八九十分左右,这就是一种正态分布。
可以看到我在这张正态分布的图片中写了两个红色的字母,分别标在最高点对应的横坐标值和它到源点的距离。其中前者其实就是这个正态分布的平均值,我们称之为 $\mu$,而 $\sigma$ 就是这个正态分布的标准差。
我们如何理解这个正态分布呢?首先这个正态分布的面积我们是可以计算的,如果说横坐标当作一个随机变量的取值的话,那么纵坐标其实就是这个取值对应的概率,由于所有概率之和应当是 $1$,所以说正态分布围成的一个图形,它的总面积,应该是等于 $1$ 的。
另外还有一个重点是关于不同正态分布平均值和方差大小的关系。

首先平均值的差异是非常好判断的,我们肉眼就可以看出这个峰值所在的横坐标大致在哪里。但是值得辨析的是,方差和正态分布的高度的关系。不要说你看这个正态分布长这么高方差一定很大,但事实恰恰相反,中部越高的正态分布图形方差反而小,应该这样考虑:中间大说明落在中部的概率大,中部的数越多就说明只会有少量的数据离平均值特别远,方差就小了。
除此之外,还有一个特殊的考点,正态分布不同位置面积的大小。
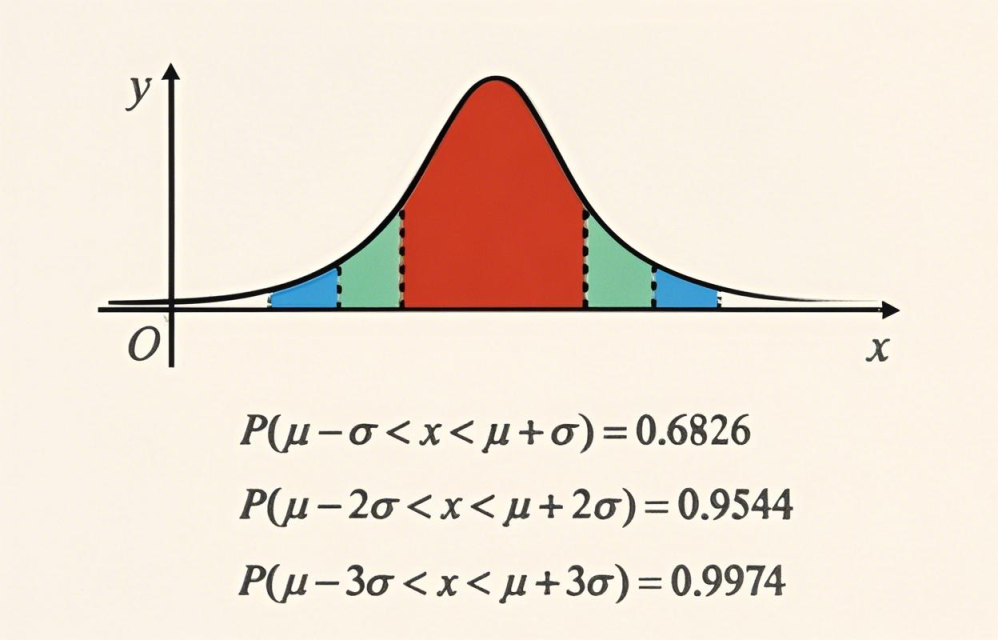
其中从平均值到两边分割线的差距都是一个标准差。但是值得注意的是在现在的教材中好像把这些数给改了,上图的符号是有误的,这里用的应该是约等号,现在从上到下对应的值应该是:0.6827、0.9545、0.9973,不过考试的时候应该是会给这些值的(
另外就是正态分布也是可以作为一个函数存在的,我们将其称为正态曲线,其解析式为:
至此,所有高中部分的基础概率的概念都算是介绍的差不多了,接下来就是编程上的内容。
基础例题:第十六把钥匙
期望性质:期望线性性
我们在做概率的编程题中,无非就是两类,一类是算概率,一类是算期望。但是由于概率是个浮点数,容易爆炸,所以说题目一般都是让我们把概率取模,也就是算逆元;当然更多的应该是计算期望,这个灵活性更大;还有就是概率题非常的玄学,有一些题目甚至是诈骗,这就让我们不得不提高警惕(
那么关于期望的例题,我们要用到的一个重要性质是期望线性性,可以表达为:
这里的 $X_1,X_2$ 是随机变量,$\alpha,\beta$ 可以是任意系数,并且对于 $X_1,X_2$ 没有任何限制(即不论这两个随机变量有无依赖关系,都可以使用该式)期望线性性的作用主要是把看上去一坨乱七八糟的期望求和式化简为更加好计算的内容,下面我举几个例子来看一下。
例题十四:给出一个有 $6$ 个面的骰子(点数为 $1\sim 6$),掷骰子 $n$ 次,求所有期望总和。
这一看就不能大力计算,这就需要用到期望线性性,设最终的总和为 $Y$,每次投出的数值是 $X_i$,那么显然的可以得知 $Y=\sum X_i$,那么我们可以直接套用期望线性性的式子变成求:
由于一眼就可以看出每一次投骰子是独立的,那么每一次的期望值都应该是一样的,那么总的期望值就可以认为是 $n$ 个$\ E(X_1)$ 相加即 $E(Y)=nE(X_1)$,这样就轻松的解决了一个看似非常难以计算的题目。
这个模型其实在上面也可以当做是二项分布的例题,所以并没有特别体现出期望线性性的优点,接下来看一个不那么明显的期望问题。
例题十五:$n$ 人每人有一顶帽子。帽子被随机重新分配,获得原来帽子的期望人数是多少?
最笨的做法:暴力枚举所有情况,然后计算。显然的一般来说这种做法是会超时的。
那么如果是期望线性性来操作这道题目又该怎么办呢?我们还是设 $Y$ 是 $n$ 个人重新分配后,拿到自己帽子的人的数量,那么题目让我们求的就是 $E(Y)$ 的值。
那么这道题我们如何设置自己的 $X_i$ 呢?因为 $Y$ 如果这样被设了人数,那么最直观的想法就是把 $X$ 也设为符合条件的人数。也就是说如果对于第 $i$ 人来说,如果他获得了自己的帽子,那么 $X_i$ 就是 $1$ 否则是 $0$。显然的如果我们这样定义,可以得到 $Y=\sum X$,$E(Y)=E(\sum X)$。
依照期望线性性的式子,可得 $E(Y)=\sum E(X)$,这时候我们看可以来分析一下每一个 $X$ 的期望值是多少。那么最后就可以计算出总共的值。
简单的计算一下,可以写出这样的式子:
我们会注意到,理论上来说,在每一次分配中,$X_i$ 的值应该是互相依赖的。因为比如说在 $3$ 个人中,$1$ 号获得了 $2$ 号的帽子,那么 $2$ 号必然拿不到帽子。但是这时候重要的点就来了,我们 $X$ 的定义,是在一轮分配中能不能拿到自己的帽子。在最开始暴力做法中也提到了,分配总共的数量有 $n!$ 个。也就是说,这一个 $X_i$ 的期望值,就包括了所有分配方案的情况。也就是说分组方式是不一样的:我们举的例子中,是按照分配来分组计算;但是这个定义的实际含义,是根据人来分组计算。所以说不管怎么说,这个人拿到自己帽子的概率应该始终是 $1/n$。
答案就一目了然了:$E(Y)=n\times(1/n)=1$。
这是期望线性性最最最最最基本的应用,事实上编程的期望计算逃不出这么几个常见的模型,继续来看几个简单的题目示例。
期望例题:得打开思路
那么先来看一道简单的概率题罢。
题目大意:随着世界杯小组赛的结束,法国,阿根廷等世界强队都纷纷被淘汰,让人心痛不已。 于是有人组织了一场搞笑世界杯,将这些被淘汰的强队重新组织起来和世界杯一同比赛。你和你的朋友欣然去购买球票。不过搞笑世界杯的球票出售方式也很特别,它们只准备了两种球票。
- A 类票——免费球票
- B 类票——双倍价钱球票。
购买时由工作人员通过掷硬币决定,投到正面的买 A 类票, 反面的买 B 类票。主办方总是准备了同样多的 A 类票和 B 类票。你和你的朋友十分幸运的排到了某场精彩比赛的最后两个位置。
这时工作人员开始通过硬币售票。不过更为幸运的是当工作人员到你们面前时他发现已无需再掷硬币了,因为剩下的这两张票全是免费票。
你和你的朋友在欣喜之余,想计算一下排在队尾的两个人同时拿到一种票的概率是多少(包括同时拿 A 类票或 B 类票) 假设工作人员准备了 $2n$ 张球票,其中 $n$ 张 A 类票,$n$ 张 B 类票,并且排在队伍中的人每人必须且只能买一张球票(不管掷到的是该买 A 还是该买 B)。
对于所有 $n$ 满足 $n\le 1250$。
这是一个经典的,简单的概率 DP,在上面讲了全概率公式和贝叶斯公式之后,我们就可以发现概率计算这一种天生的分类分布的过程,非常适合递推的结构,所以说概率题和期望题,大都是计数 DP 或者各种奇奇怪怪的 DP。
来看看这道题目,$n$ 很小,可以直接考虑开二维数组。那么就建立状态 $dp[i][j]$ 表示售出 $i$ 张 A 票,$j$ 张 $B$ 票后两人买到票相同的概率。初始条件是显然的,如果出售的票是同一种票(当然前提是卖出出了至少有两张票)时候拿同样票的概率是 $100\%$,状态转移方程也是非常好理解的:
这是因为每次卖出一张票,只能是二选一,并且卖的票由抛硬币决定,所以说转移方程可以写成这样。
1 |
|
继续,看一道期望题。
题目大意:现在帕琪与强大的夜之女王,吸血鬼蕾咪相遇了,夜之女王蕾咪具有非常强大的生命力,普通的魔法难以造成效果,只有终极魔法:帕琪七重奏才能对蕾咪造成伤害。帕琪七重奏的触发条件是:连续施放的 $7$ 个魔法中,如果魔法的属性各不相同,就能触发一次帕琪七重奏。
请注意,无论前 $6$ 个魔法是否已经参与施放终极魔法,只要连续 $7$ 个魔法的属性各不相同,就会再触发一次终极魔法。例如,如果用序号来代表一种魔法,魔法的施放序列为 $1, 2, 3, 4, 5, 6,7, 1$,则前 $7$ 个魔法会触发一次终极魔法,后 $7$ 个魔法会再触发一次终极魔法。
现在帕琪有 $7$ 种属性的能量晶体,第 $i$ 种晶体可以施放出属性为 $i$ 的魔法,共有 $a_i$ 个。每次施放魔法时,会等概率随机消耗一个现有的能量晶体,然后释放一个对应属性的魔法。
现在帕琪想知道,她触发帕琪七重奏的期望次数是多少,可是她并不会算,于是找到了学 OI 的你。
数据范围约定:$\sum a_i\le 10^9$。
这一个问题也是类似于期望线性性的问题,来看一看:我们同样的设 $Y$ 为释放七重奏的次数,$X_i$ 为第 $i$ 次是否释放七重奏,显然要求 $i\ge7$,问题就被转化为计算所有$\ E(X_i)$ 的和。
首先来考虑$\ E(X_7)$ 即第七次释放七重奏的期望,显然的期望值就等于第七次释放七重奏的概率。如果设总共有 $N$ 个水晶的话(即 $N=\sum a_i$ )那么第一次释放七重奏的概率应该是:
那么接下来来看看在第八次唱咒语释放七重奏的概率,其实就是在刚刚第七次唱咒语释放七重奏的基础上再使用任意一个晶片,我们会发现共同部分是第七次唱咒语触发七重奏的这个式子,提取公因式之后剩下的部分加起来:
乘了和乘了似的,所以直接忽略掉它,也就是说第八次唱咒语释放七重奏的概率和第七次一样!那么同理可得,每一次唱咒语结束以后释放七重奏的概率都是一样的(当然前提条件还是唱咒语次数大于等于 $7$,不然你连次数都不够)那么这一个总的答案就应该是:
那么代码也就好写了(
1 |
|
接下来看一个重要的模型:随机游走模型。
进阶例题:苦药似的真理
游走模型:空域的壁垒
例题十六:有 $n$ 种类型的优惠券,每次购买可以随机获得一张优惠券。期望购买多少次可以集齐所有类型的优惠券。
这里就需要用到一个小结论:如果每次试验的成功概率为 $p$,那么成功的预期次数为 $1 / p$。
证明:如果每次试验的成功概率为 $p$,那么成功的预期次数为 $1 / p$。
我们定义两个状态:$X_0,X_1$ 分别表示没成功与成功了,他们对应的期望值 $E(X_0),E(X_1)$ 表示这个状态转向试验成功的期望次数,那么可以写出下面的线性方程组。
那么简单理解一下这个方程组的含义,就是试验一次,然后成功了与多试验一次没有成功,那么期望继续试验$\ E(X_0)$ 次成功,这样就是$\ E(X_0)$ 的定义,从不成功转向成功的期望试验次数。
最终可以很轻松的解得 $E(X_0)=1/p$,证毕!
有了这个小结论,我们可以简单的来看一下这道题是什么。
同样的我们设 $Y$ 为现在有了 $n$ 种类型的优惠券的购买次数,$X_i$ 为有了 $i-1$ 种优惠券,然后获得下一种优惠券的购买次数。那么再次可以列出那熟悉的式子:
接下来我们来简单的计算一下每一个 $E(X)$ 的值。
- $E(X_1) = 1$:因为当前一张优惠券都没有,拿哪一张都会多一种。
- $E(X_2)=n/(n-1)$:当前有了 $1$ 种,会有 $(n-1)/n$ 的概率获得新的一种,$1/n$ 的概率获得相同的,所以根据上面的结论可以知道期望次数为 $1/((n-1)/n)$,即 $n/(n-1)$。
- $E(X_3)=n/(n-2)$:同理。
最终可以得到答案是:
学过小学的我们都知道,这是一个调和级数,所以说期望应该是买 $\log n$ 次。
不过说这只是随机游走模型的一个式子意义下的理解,随机游走模型远比这玩意要逆天,我们拿一开始的那个小结论举例,可以画出下面这样的图来表示随机游走的过程:
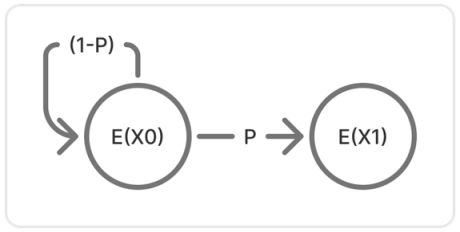
可以看出,随机游走可以抽象成一个图论问题,而且这个图论问题是可以写成方程组的形式的。还是以这个图为例,我们设定了两个状态以后,列出的方程组:
其实也是根据这张图可以理解的。这就为我们打开了一个新的思路,可以依据随机游走模型列出方程组,并且这个方程组一定是可解的,可以通过高斯消元的形式解出方程组的解,就是另外一种计算期望的形式。
模型例题:世界的大门
虽然说各大网站和博文都说需要结合高斯消元优化,但我并没有找到
刚说没找到就找到了( 题目传送门
题目大意:$n$ 行 $m$ 列的矩阵,现在在 $(x,y)$,每次等概率向左,右,下走或原地不动,但不能走出去,问走到最后一行期望的步数。
注意,$(1,1)$ 是木板的左上角,$(n,m)$ 是木板的右下角。$n,m\le 10^3$。
题目的意思是非常好理解的,根据题目我们可以轻松的得到递推式:
可以发现,我们其实还有一个特殊情况就是当 $M=1$ 的时候,这个递推式应该是非法的,它访问了不应该存在的元素,所以要提前特判掉,这个和普通的随机游走模型式一样的,可以列出方程式:
化简后得到第二个式子,考虑倒推着做,那么答案即为 $2\times(N-x)$,$x$ 是初始横坐标。
和刚刚一样的,我们会发现机器人不能往上走,这就意味着 $dp[i][j]$ 的推导需要用到 $dp[i + 1][j]$,但 $dp[i+1][j]$ 的推导却用不到 $dp[i][j]$,这也是刚刚我们倒推着做的原因。那么同样在这里也可以用这样的思路,于是用 $dp[i+1][j]$ 作为已知数,剩余的作为未知数,可以把刚刚的方程组化为下面这样:
并且考虑到精度问题,我们可以发现每一个式子的分母都是一样的,可以化掉,并利用高斯消元解这个方程式,可以列出像下面这样的系数矩阵:(以 $4\times 4$ 的矩阵为例)
很显然,如果我们是常规的高斯消元的话,$O(n^3\times n)$ 即高斯消元复杂度乘以总行数,这样的复杂度我们完全是吃不消的,这时候就会注意到系数矩阵有一个很特殊的性质,就是每一行最多有用的系数只有三个,那么高斯消元就不必一行一行的消,即我们要考虑除了高斯消元以外更快的消元方式。
可以观察到由于上下两行始终只差一个格子,所以可以按照倍率每一次消掉多余的那一个,就可以得到一个上三角的结果,最后直接套用并计算即可。这样的话复杂度就会降到 $O(NM)$,其中 $M$ 是每行消元和计算的复杂度。
友情链接:
还有一个被遗忘的点,就是忘记说动规初始值了,显然初始值最后一行就已经不用移动了,所以初始值是最后一行的值全为 $0$。
1 |
|
算法实战:甜饵般的答案
查看相关算法标签喵!
参考资料(以下排名不分先后)